
For the last two years, every DAM vendor pitch has ended with the same slide: “and now, with AI.” Auto-tagging, similarity search, background removal, generative variants. Useful, in places. Inconsistent, in others. But fundamentally a feature layer bolted onto the same DAM model we have lived with since the early 2010s.
2026 is different. The shift toward AI agents — software that doesn’t just suggest a tag but actually plans, executes, and chains tasks across the content lifecycle — changes the conversation from “what can AI do inside my DAM?” to “what does my DAM need to look like so AI can work through it?”
This is no longer a feature debate. It is an operating-model debate. And like any operating-model debate, the answer is more nuanced than the demos suggest.
Strip away the marketing and there are five practical patterns emerging across the vendor landscape:
1. Enrichment agents — generating metadata, alt-text, summaries, audience classifications and taxonomic tags at the point of ingestion or in bulk across legacy libraries. Bynder’s published agent library, for instance, includes a Multilingual Metadata Generator, an Audience Classification Agent, a People Count Detection Agent, and a Visual Motifs & Themes Detection Agent — each driven by natural-language prompts rather than custom code.
2. Transformation agents — adapting a single source asset into market-, channel-, or campaign-specific variants. Reframing for Instagram. Localizing on-image text and visible context for a French or German market. Generating ten A/B test variations from one master. This is the “asset goes the extra mile” use case that Aprimo, Adobe (via Firefly + AEM Assets), Bynder Studio and Papirfly are all racing to industrialize.
3. Brand & compliance agents — checking logo placement, color usage, accessibility (WCAG/ADA), restricted objects, profanity, sustainability claims, and even regulatory specifics like France’s Loi Evin for alcohol advertising. This is where DAM stops being a library and starts being a gate.
4. Governance agents — looking outward. Scanning the web and marketplaces for unauthorized usage, expired stock licenses, counterfeit listings or off-brand reuse. Tracking content ROI by aggregating real usage data across owned and external channels.
5. Intelligent automation / orchestration — multi-step agents that chain the above together: ingest a hero image, classify the audience, run brand-compliance checks, generate three localized variants, route for human approval, syndicate to channels. This is the layer where DAM converges with content operations and MarTech orchestration.
A useful frame I keep coming back to: AI agents are not just new features in the DAM. They are new consumers of the DAM. The user base has expanded from humans to humans-plus-agents, and that has architectural consequences. The diagram below frames how those layers fit together.
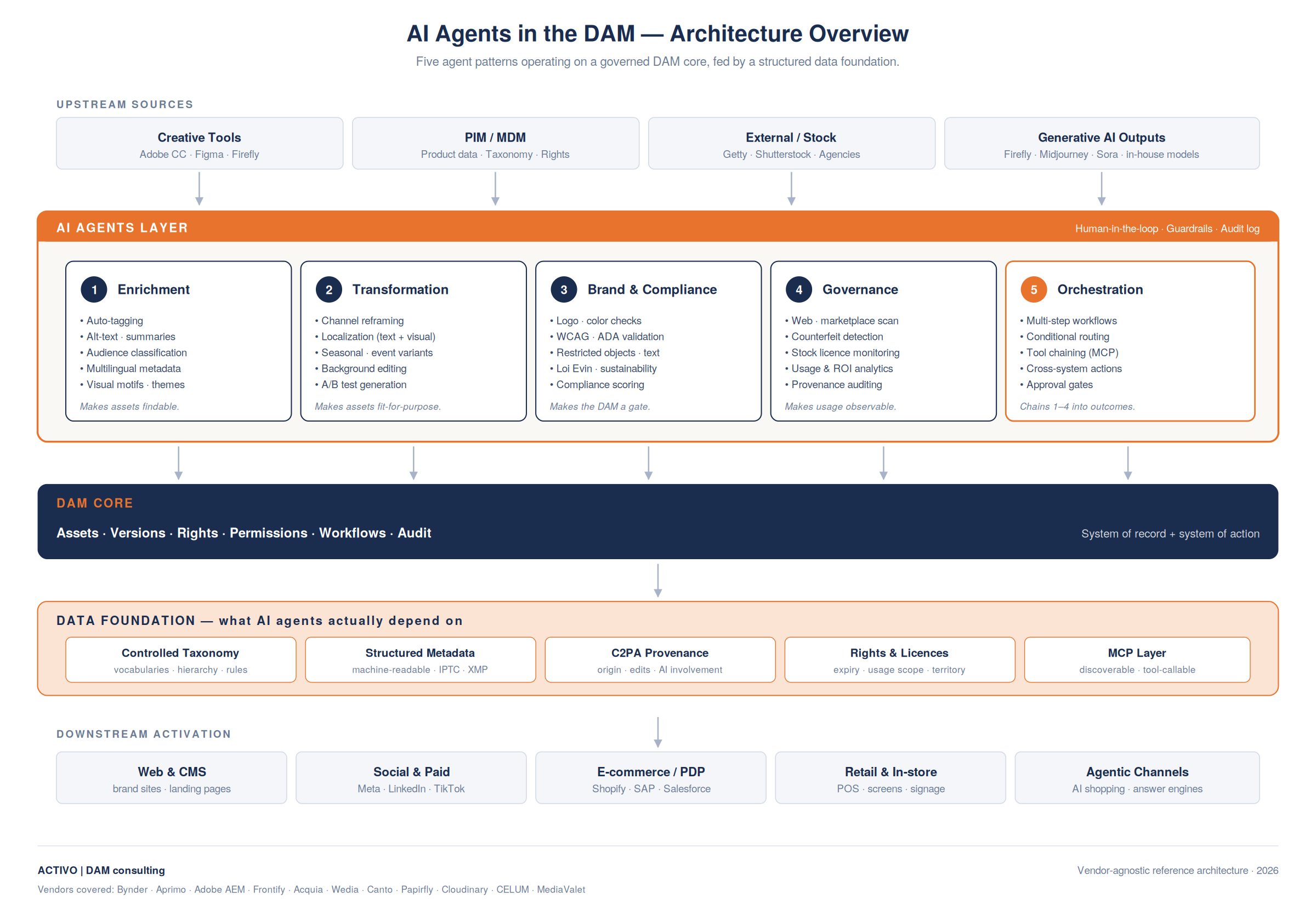
Figure 1 — AI Agents in the DAM: reference architecture (Activo, 2026).
Three independent pieces of 2026 research help anchor this in evidence rather than vendor optimism: Bynder’s State of DAM 2026 (1,800 managers across seven markets in companies with 1,000+ employees), the WoodWing-supported State of AI in DAM & Content Operations report (271 professionals, authored by independent consultant Kristina Huddart), and the Forrester Wave Q1 2026 for DAM systems.
Adoption has crossed the threshold from optional to expected.
• 97% of companies say their content operations have been impacted by AI-driven market trends.
• 30% expect AI to positively impact top-line growth in the next 12 months — up from 24% the year before.
• 50% of organizations with fully integrated AI in their DAM report fully personalized content delivery, versus only 28% of those at early stages of AI adoption.
But maturity is uneven, and self-assessment is humbler than the headlines suggest.
• Self-reported AI success in DAM/content operations sits at just 54%, and organizational readiness scores 3 out of 5 (Huddart, 2026).
• Personal AI appetite among practitioners averages 7.25/10 — well ahead of the infrastructure to match it.
The top barriers are operational, not technological.
• Data privacy and security: 41%
• Skill development: 36%
• Integration complexity: 35%
Governance concerns dominate where AI touches outbound content.
• Content quality control: 55%
• Risk management: 50%
• Compliance: 47%
• 9 in 10 respondents view human oversight as essential, with 54% considering it “very important.”
ROI is being measured in time, not dollars — yet.
• 40% measure AI ROI through time savings; only 36% through cost reduction.
• Top three ROI areas for fully-integrated organizations: improved search and asset discovery (41%), faster time-to-market (37%), and workflow efficiency (37%).
• Vendor case studies report concrete numbers — Bynder claims 180+ workdays saved per year on alt-text generation alone for enrichment-heavy customers.
The honest read: the appetite for AI agents has outrun the readiness for them. The organizations getting value are doing the unglamorous work — clean metadata, governance, KPIs, change management — at the same time as the deployment, not after it.
When agents work, they work hard. The published numbers and customer case studies are starting to settle into recognizable patterns:
• Time on metadata collapses. Tasks that used to consume entire roles become background processes. The 180+ workdays/year figure on alt-text alone is just the visible tip.
• Time-to-market shrinks for localized and channel-specific variants — particularly powerful for brands operating across 20+ markets where the bottleneck has always been creative production capacity, not strategy.
• Brand and regulatory risk becomes auditable. Compliance moves from “we hope the agency followed the guidelines” to “every asset has a compliance score, a flagged-deviations list and a timestamped audit trail.”
• Discoverability scales with library size, not against it. The traditional DAM curse — the bigger the library, the harder it is to find anything — starts to invert when enrichment is consistent, multilingual and audience-aware.
• Content ROI becomes measurable. Governance agents that track usage across channels finally close the loop on the perennial board-level question: “what is our DAM actually returning?”
There is also a quieter benefit that practitioners notice before executives do: agents change what humans do all day. The DAM administrator stops applying tags and starts designing prompts, defining guardrails and tuning compliance scoring. The role becomes more strategic and more technical at the same time.
This is where the vendor decks get quieter. The constraints are real and worth naming clearly.
Model quality is uneven across asset types. General-purpose vision models do well on common objects and scenes. They struggle with brand-specific context, niche product taxonomies, regulated-industry semantics, and anything requiring institutional knowledge of your business. The first wave of DAM AI failed precisely here: auto-tagging that could not distinguish your three product families from each other.
Hallucination has not gone away. Enrichment agents will confidently generate plausible-but-wrong descriptions. Compliance agents will miss subtle deviations and flag false positives. The mature posture is human-in-the-loop on anything that touches brand, legal or regulatory surfaces — explicitly designed into Bynder’s AI Control Center, and addressed differently by Aprimo, Adobe and Frontify.
Cost models are still settling. Per-asset, per-agent-run, per-token, bundled into license, premium add-on — every vendor is pricing differently, and TCO comparisons are genuinely hard right now. Aprimo’s enhanced AI is a paid add-on. Bynder bundles agents into its platform. Adobe ties Firefly credits to AEM. The cost of running 200,000 enrichment passes per month is not trivial, and it scales with library activity.
Governance complexity goes up before it goes down. More agents mean more prompts, more guardrails, more audit logs, more permissions to manage. Without discipline, you trade one form of chaos (untagged assets) for another (a sprawl of poorly-documented agents that nobody owns).
Integration debt is the silent killer. An agent that lives only inside the DAM is a half-solution. The value comes when it can read from PIM, write to CMS, trigger workflows in Workfront or equivalent, push to retail syndication and pull usage signals back. The Model Context Protocol (MCP), the open standard developed by Anthropic, is emerging as the lingua franca here — and the dampioneers analysis is right to argue that MCP readiness should be treated as a current DAM selection criterion, not a future consideration.
Vendor lock-in shifts shape. When your agents, prompts, taxonomies and compliance rules all live inside one DAM’s proprietary agent platform, switching costs go up substantially. The composable, MCP-mediated alternative is more portable but currently less mature.
Here is the part the demos rarely cover: AI agents are only as good as the data they sit on top of. And in most enterprise DAMs, that data is not where it needs to be.
Three data prerequisites separate organizations that get value from AI agents from those that get expensive disappointment:
1. A real, maintained taxonomy. Not a folder structure with aspirations. A taxonomy with controlled vocabularies, applied consistently, governed by someone with authority. Multi-agent systems thrive when they share a common schema, and as one industry analysis put it bluntly, metadata applied haphazardly introduces the very ambiguity it is designed to resolve. If your current DAM has 40% of assets with empty metaproperties, no agent — Bynder’s, Aprimo’s, or anyone else’s — will fix that for you. It will inherit it.
2. Structured, machine-readable metadata. Free-text descriptions are fine for human browsing. They are weak fuel for agents. The shift toward agentic e-commerce is making this concrete: AI shopping agents are starting to use structured product data to decide what to recommend and what to ignore. Assets with incomplete or unstructured metadata are increasingly being flagged as low-confidence and dropped from consideration.
3. Provenance and rights data. As C2PA, IPTC Media Provenance and similar standards mature, agents will need clear answers to: who created this, when, with what tools, with what rights, and through which approval chain. DAMs that already capture this will be agent-ready in a way that DAMs treating provenance as an afterthought will not. (More on this in the next section.)
There is also the freshness dimension: agents making real-time decisions on stale data behave erratically. Refresh cadence, lineage and source-of-truth alignment with PIM, MAM and CMS systems matter more once agents are in the loop than they did when humans were the only consumers — humans tolerate inconsistency by exception; agents propagate it at scale.
The uncomfortable truth, repeated by every credible analysis I have read in 2026, is that organizations underinvest in data foundations and overinvest in model selection. McKinsey’s own work suggests around 70% of generative-AI initiatives hit data-related challenges. In DAM specifically, this manifests as enrichment agents that produce nothing useful because the source taxonomy is inconsistent, or governance agents that flag everything because the brand guidelines were never digitized into machine-checkable rules.
If 2024–2025 was the era of “can the model do it?”, 2026 is the era of “can you prove what it did, with whose data, under which rules?” For DAM teams, three converging forces — content authenticity standards, the EU AI Act, and unresolved training-data ethics — turn provenance from a nice-to-have into part of the compliance perimeter.
Content authenticity has matured into infrastructure.
The C2PA specification (Coalition for Content Provenance and Authenticity), founded by Adobe, Microsoft, Google, BBC and Intel, embeds cryptographically signed manifests directly inside media files. The C2PA v2.0 spec was ratified in 2024, the Conformance Program launched mid-2025, and the Content Authenticity Initiative now counts more than 6,000 members globally. IPTC’s 2025.1 release adds four AI-specific fields to the IPTC Photo Metadata Standard. Sony’s PXW-Z300 brings Content Credentials into capture, and France Télévisions began publishing C2PA-signed news programs in late 2025 — exactly the kind of adoption signal that pulls every downstream system, including DAMs, into the standard. Coverage from the IPTC Media Provenance Summit in Toronto (April 2026) made clear that the news industry is already moving from pilot to production.
For DAM specifically, this turns into four concrete questions:
• Preservation on ingestion. Does the DAM preserve existing XMP and C2PA metadata when ingesting assets, or does it silently strip them during transcoding?
• Preservation on export. Do export pipelines re-embed IPTC and C2PA fields, or does the default preset remove all metadata to reduce file size?
• Injection capability. Can the DAM write IPTC 2025.1 AI fields onto assets that arrived without them — for instance, raw outputs from Midjourney or Stable Diffusion?
• C2PA re-signing. If the DAM modifies metadata, can it re-sign the C2PA manifest? Without re-signing, the chain breaks and downstream verifiers reject the asset.
The EU AI Act becomes operationally binding on 2 August 2026.
From that date, Article 50 transparency duties apply: providers and deployers must ensure that AI-generated or AI-modified content (including images and video) is clearly labelled as such. General-purpose AI model providers must publish a public summary of their training data and maintain a copyright compliance policy. Penalties reach €35M or 7% of global turnover, whichever is higher. For organizations operating in the EU — and that includes most of the DAM customer base I work with — this puts new requirements on every downstream system that touches AI-generated assets, including the DAM. “We didn’t know it was AI-generated” will not be a defensible position from August 2026 onward.
The training-data ethics question won’t resolve itself in 2026.
The EU Copyright Directive lets creators reserve rights against AI training, and the AI Act requires GPAI providers to publish training-data summaries — but the practical mechanics are still being negotiated in case law and Codes of Practice. For DAM teams, the relevant ethical questions are concrete: are the generative tools your organization uses trained on data sets your legal team would be comfortable defending? When you fine-tune on your own brand assets, are you also locking in any biased patterns those assets carry? When AI-localizes a campaign for a market you under-represent in your training data, is the output authentically appropriate, or quietly mediocre? Bias toward English-language and dominant cultural patterns is well-documented in leading models, and the only mitigation in DAM workflows is structured human review at the points where the agent meets the market.
Three operational moves I’d suggest right now:
• Treat C2PA preservation, injection and re-signing as procurement criteria. Most DAM vendors are still early here; ask for a demo with real signed assets, not a roadmap slide.
• Add an AI-content register. Every asset generated or substantively modified by AI gets a flag, the model name, the prompt, the operator, the timestamp, and a review status. This is what Article 50 audit-readiness looks like in practice.
• Codify your AI ethics policy in machine-checkable rules where you can. “Do not generate images of identifiable real people”, “do not localize wellness claims into FR/DE without legal review”, “tag every fully-AI-generated asset as such on export”. Compliance agents enforce what is structured. They cannot enforce what lives only in a PDF policy doc.
Provenance is not a feature your DAM either has or hasn’t. It is a chain — capture, ingestion, edit, export, publication — and the DAM is the link in that chain most organizations control most directly.
A few practical points I find myself repeating to clients:
• Audit your metadata before you buy your agents. A two-week metadata health assessment usually saves a six-figure mistake.
• Treat MCP support and C2PA support as procurement criteria, even if you do not have an immediate use case. Optionality has a value.
• Resist the “configure 20 agents in week one” temptation. Start with two or three high-volume, low-risk use cases (alt-text, simple enrichment, basic reframing). Measure. Tune. Then expand.
• Codify your brand, compliance and ethics rules into a structured form before you ask an agent to enforce them. “On-brand” is not a prompt; it is a checklist that needs to exist somewhere agents can read.
• Plan for August 2026 now, not in July. EU AI Act Article 50 transparency duties become applicable in three months. AI-content labelling, training-data summaries and audit-readiness are the practical asks.
• Invest in the human role. The DAM librarian of 2024 is becoming the agent operator of 2026. Different skill profile, likely a different person.
• Stay vendor-agnostic where you can. Bynder, Aprimo, Adobe, Frontify, Acquia, MediaValet, Wedia, Canto, Papirfly, Cloudinary, CELUM — all moving in broadly similar directions, with very different architectures, pricing and integration philosophies. Best fit depends on your content volume, regulatory profile, geographic footprint, and how much of the agent stack you want to own versus consume.
Agentic AI in DAM is genuinely exciting, and for the first time in a long time, the gap between the demos and what production systems can deliver is closing. But the value will not be evenly distributed. It will accrue to organizations that did the unglamorous work — taxonomy, metadata, provenance, governance, integration architecture — before the agents arrived.
The agents are arriving anyway. The only question is whether they will find anything useful, and anything trustworthy, to work with when they get here.
Sources referenced: Bynder State of DAM 2026 (1,800 managers, 7 markets); Huddart / WoodWing State of AI in DAM & Content Operations 2026 (271 professionals); Forrester Wave Q1 2026 DAM Systems; Content Authenticity Initiative (contentauthenticity.org); IPTC Media Provenance Summit Toronto 2026; C2PA v2.0 specification; EU AI Act (Regulation 2024/1689) — Article 50 and GPAI provisions applicable Aug 2 2026; dampioneers analysis on MCP readiness; McKinsey on GenAI implementation challenges.





