
Depuis deux ans, chaque démo d'éditeur DAM se termine sur la même slide : « et maintenant, avec l'IA ». Auto-tagging, recherche par similarité, suppression d'arrière-plan, génération de variantes. Utile, parfois. Inégal, souvent. Mais fondamentalement une couche de fonctionnalités greffée sur le même modèle DAM avec lequel nous vivons depuis le début des années 2010.
2026 est différent. L'arrivée des agents IA — des logiciels qui ne se contentent plus de suggérer un tag mais qui planifient, exécutent et enchaînent des tâches sur tout le cycle de vie du contenu — déplace la question. On ne se demande plus « qu'est-ce que l'IA peut faire dans mon DAM ? » mais « à quoi mon DAM doit-il ressembler pour que l'IA puisse travailler à travers lui ? »
Ce n'est plus un débat de fonctionnalités. C'est un débat de modèle opérationnel. Et comme tout débat de modèle opérationnel, la réponse est plus nuancée que ce que les démos laissent croire.
Une fois le marketing mis de côté, cinq familles d'agents émergent dans le paysage des éditeurs :
1. Agents d'enrichissement — génération de métadonnées, alt-text, résumés, classification d'audience et tags taxonomiques à l'ingestion ou en masse sur des bibliothèques existantes. La bibliothèque d'agents publiée par Bynder, par exemple, comprend un Multilingual Metadata Generator, un Audience Classification Agent, un People Count Detection Agent et un Visual Motifs & Themes Detection Agent — chacun piloté par des prompts en langage naturel, sans code.
2. Agents de transformation — adaptation d'un asset source unique en variantes par marché, par canal ou par campagne. Recadrage pour Instagram. Localisation du texte intégré et du contexte visuel pour les marchés français ou allemand. Génération de dix variantes pour de l'A/B testing à partir d'un master. C'est le cas d'usage « l'asset va plus loin » qu'Aprimo, Adobe (via Firefly + AEM Assets), Bynder Studio et Papirfly cherchent tous à industrialiser.
3. Agents de marque et de conformité — vérification du placement de logo, des couleurs, de l'accessibilité (WCAG/ADA), des objets restreints, du langage interdit, des allégations environnementales, et même de réglementations spécifiques comme la Loi Evin pour la publicité de l'alcool. C'est là que le DAM cesse d'être une bibliothèque pour devenir un point de contrôle.
4. Agents de gouvernance — qui regardent vers l'extérieur. Scan du web et des marketplaces pour détecter les usages non autorisés, les licences stock expirées, les listings contrefaits ou la réutilisation hors charte. Suivi du ROI des contenus en agrégeant les données d'usage réelles sur les canaux propriétaires et externes.
5. Automatisation intelligente / orchestration — agents multi-étapes qui chaînent les précédents : ingérer une image hero, classer l'audience, lancer les contrôles de marque, générer trois variantes localisées, router pour validation humaine, syndiquer vers les canaux. C'est la couche où le DAM converge avec les opérations de contenu et l'orchestration MarTech.
Un cadre auquel je reviens souvent : les agents IA ne sont pas que de nouvelles fonctionnalités dans le DAM. Ce sont de nouveaux consommateurs du DAM. La base d'utilisateurs s'est élargie des humains aux humains-plus-agents, et cela a des conséquences architecturales. Le schéma ci-dessous resitue l'articulation de ces couches.
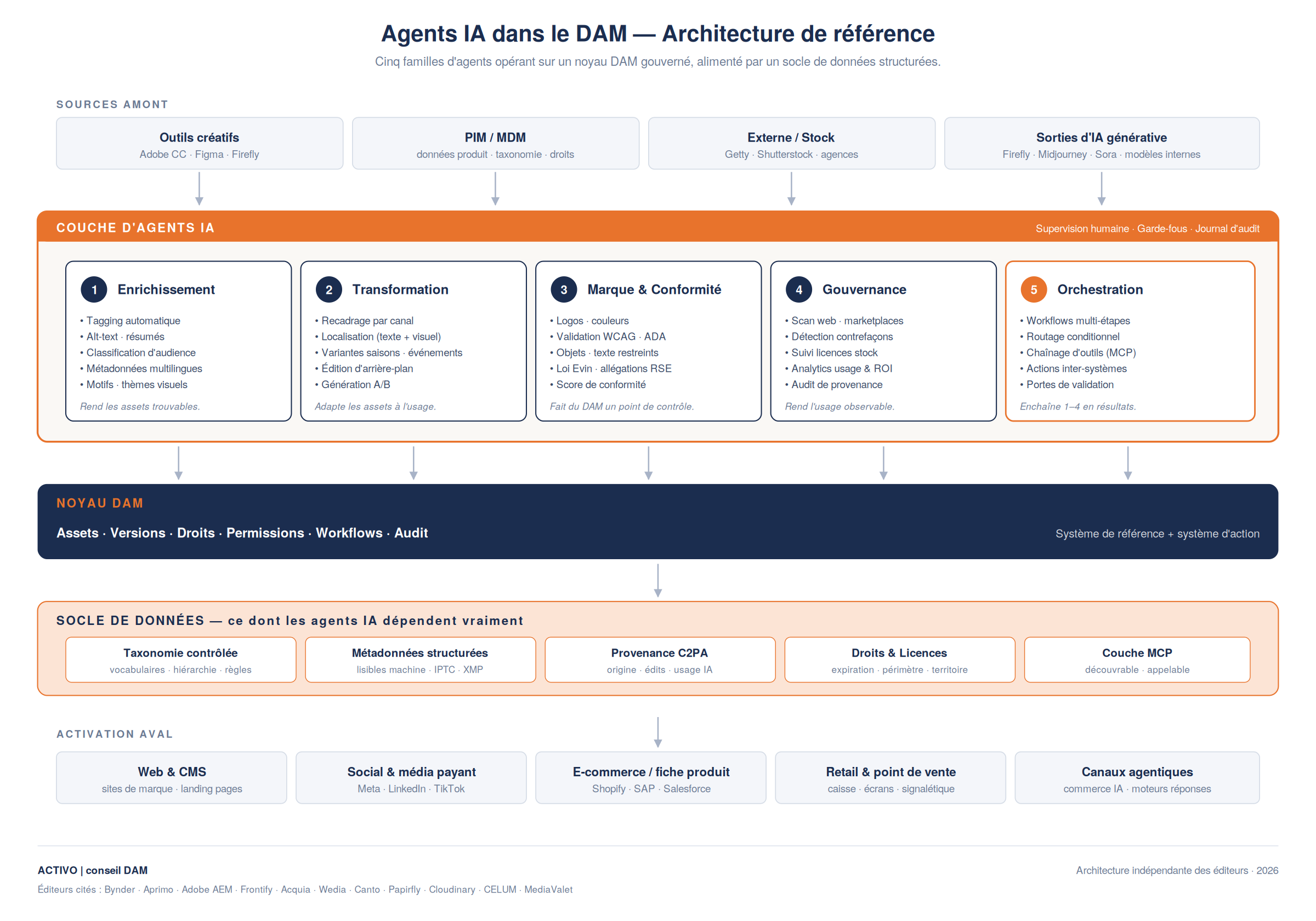
Figure 1 — Agents IA dans le DAM : architecture de référence (Activo, 2026).
Trois travaux indépendants de 2026 permettent d'ancrer le sujet dans des données plutôt que dans l'optimisme des éditeurs : le State of DAM 2026 de Bynder (1 800 managers dans sept marchés, entreprises de plus de 1 000 salariés), le State of AI in DAM & Content Operations soutenu par WoodWing (271 professionnels, étude indépendante de Kristina Huddart) et la Forrester Wave Q1 2026 sur les systèmes DAM.
L'adoption a franchi le seuil de l'optionnel à l'attendu.
• 97 % des entreprises déclarent que leurs opérations de contenu ont été impactées par les tendances liées à l'IA.
• 30 % attendent un impact positif de l'IA sur la croissance du chiffre d'affaires dans les 12 prochains mois — contre 24 % l'année précédente.
• 50 % des organisations qui ont pleinement intégré l'IA à leur DAM rapportent une diffusion de contenu entièrement personnalisée, contre seulement 28 % de celles qui en sont aux premières étapes.
Mais la maturité est inégale, et l'auto-évaluation est plus modeste que les gros titres.
• Le succès auto-déclaré de l'IA en DAM/opérations de contenu plafonne à 54 %, et la maturité organisationnelle se note 3 sur 5 (Huddart, 2026).
• L'appétence personnelle des praticiens atteint 7,25 sur 10 en moyenne — bien au-delà de l'infrastructure pour la suivre.
Les obstacles principaux sont opérationnels, pas technologiques.
• Confidentialité et sécurité des données : 41 %
• Développement des compétences : 36 %
• Complexité d'intégration : 35 %
Les préoccupations de gouvernance dominent dès que l'IA touche au contenu sortant.
• Contrôle qualité du contenu : 55 %
• Gestion des risques : 50 %
• Conformité : 47 %
• 9 répondants sur 10 considèrent la supervision humaine comme essentielle, dont 54 % qui la jugent « très importante ».
Le ROI se mesure en temps, pas encore en euros.
• 40 % mesurent le ROI de l'IA via les gains de temps ; seulement 36 % via la réduction des coûts.
• Top 3 des zones de ROI pour les organisations pleinement intégrées : amélioration de la recherche et de la découverte (41 %), accélération du time-to-market (37 %), efficacité des workflows (37 %).
• Les case studies d'éditeurs avancent des chiffres concrets — Bynder revendique 180+ jours-homme économisés par an sur la seule génération d'alt-text pour les clients à fort volume d'enrichissement.
La lecture honnête : l'appétit pour les agents IA a devancé la maturité organisationnelle. Les organisations qui en tirent de la valeur font le travail ingrat — métadonnées propres, gouvernance, KPIs, conduite du changement — en parallèle du déploiement, pas après.
Quand les agents fonctionnent, ils travaillent dur. Les chiffres publiés et les case studies clients commencent à dessiner des motifs reconnaissables :
• Le temps consacré aux métadonnées s'effondre. Des tâches qui consommaient des postes entiers deviennent des processus de fond. Les 180+ jours-homme par an sur l'alt-text seul ne sont que la partie visible.
• Le time-to-market raccourcit pour les variantes localisées et adaptées par canal — particulièrement pour les marques opérant sur 20+ marchés où le goulot d'étranglement n'a jamais été la stratégie, mais la capacité de production créative.
• Le risque marque et réglementaire devient auditable. La conformité passe de « espérons que l'agence a suivi la charte » à « chaque asset a un score de conformité, une liste d'écarts signalés et une piste d'audit horodatée ».
• La trouvabilité passe à l'échelle de la bibliothèque, au lieu de s'y opposer. La malédiction historique du DAM — plus la bibliothèque grossit, plus il est dur d'y trouver quelque chose — commence à s'inverser quand l'enrichissement est cohérent, multilingue et conscient de l'audience.
• Le ROI du contenu devient mesurable. Les agents de gouvernance qui suivent l'usage à travers les canaux ferment enfin la boucle sur la question éternelle au comité : « qu'est-ce que notre DAM nous rapporte vraiment ? »
Il y a aussi un bénéfice plus discret que les praticiens repèrent avant les dirigeants : les agents changent ce que les humains font de leurs journées. L'administrateur DAM cesse de poser des tags pour concevoir des prompts, définir des garde-fous et calibrer le scoring de conformité. Le rôle devient à la fois plus stratégique et plus technique.
C'est là que les decks d'éditeurs deviennent plus discrets. Les contraintes sont réelles et méritent d'être nommées clairement.
La qualité des modèles est inégale selon les types d'assets. Les modèles de vision généralistes performent bien sur les objets et scènes communs. Ils peinent sur le contexte spécifique d'une marque, les taxonomies produits de niche, la sémantique d'industries régulées, et tout ce qui demande de la connaissance institutionnelle de votre métier. La première vague d'IA dans le DAM a échoué précisément ici : un auto-tagging incapable de distinguer vos trois familles de produits.
L'hallucination n'a pas disparu. Les agents d'enrichissement génèrent en toute confiance des descriptions plausibles-mais-fausses. Les agents de conformité ratent des écarts subtils et soulèvent des faux positifs. La posture mature consiste à garder l'humain dans la boucle sur tout ce qui touche à la marque, au juridique ou au réglementaire — explicitement intégré dans l'AI Control Center de Bynder, et abordé différemment par Aprimo, Adobe et Frontify.
Les modèles de pricing se cherchent encore. Par asset, par exécution d'agent, par token, inclus dans la licence, en option premium — chaque éditeur facture différemment, et les comparaisons de TCO sont aujourd'hui difficiles. L'IA avancée d'Aprimo est une option payante. Bynder intègre les agents à sa plateforme. Adobe couple les crédits Firefly à AEM. Le coût d'exécuter 200 000 passes d'enrichissement par mois n'est pas négligeable, et il monte avec l'activité.
La complexité de gouvernance augmente avant de diminuer. Plus d'agents signifie plus de prompts, plus de garde-fous, plus de logs d'audit, plus de permissions à gérer. Sans discipline, on troque un type de chaos (assets non taggés) contre un autre (une prolifération d'agents mal documentés dont personne n'est propriétaire).
La dette d'intégration est le tueur silencieux. Un agent qui ne vit qu'à l'intérieur du DAM est une demi-solution. La valeur arrive quand il peut lire dans le PIM, écrire dans le CMS, déclencher des workflows dans Workfront ou équivalent, pousser vers la syndication retail et récupérer les signaux d'usage. Le Model Context Protocol (MCP), standard ouvert développé par Anthropic, émerge comme la lingua franca — et l'analyse de dampioneers a raison de soutenir que la maturité MCP devrait être un critère de sélection DAM dès aujourd'hui, pas une considération future.
Le verrouillage éditeur change de forme. Quand vos agents, prompts, taxonomies et règles de conformité vivent tous dans la plateforme propriétaire d'un seul DAM, le coût de switch monte fortement. L'alternative composable, médiée par MCP, est plus portable mais aujourd'hui moins mature.
Voilà ce que les démos couvrent rarement : les agents IA ne valent que la qualité des données sur lesquelles ils s'appuient. Et dans la plupart des DAM d'entreprise, ces données ne sont pas au niveau requis.
Trois prérequis distinguent les organisations qui tirent de la valeur des agents IA de celles qui en récoltent une déception coûteuse :
1. Une vraie taxonomie, maintenue. Pas une arborescence de dossiers avec des ambitions. Une taxonomie avec des vocabulaires contrôlés, appliqués de manière cohérente, gouvernée par quelqu'un qui en a l'autorité. Les systèmes multi-agents ne fonctionnent que s'ils partagent un schéma commun, et comme l'a dit sans détour une analyse récente, des métadonnées appliquées au petit bonheur introduisent l'ambiguïté qu'elles sont censées résoudre. Si votre DAM a aujourd'hui 40 % d'assets avec des métapropriétés vides, aucun agent — celui de Bynder, d'Aprimo ou d'un autre — ne corrigera cela pour vous. Il en héritera.
2. Des métadonnées structurées, lisibles par la machine. Les descriptions en texte libre conviennent à la navigation humaine. Elles sont un mauvais carburant pour les agents. Le glissement vers le commerce agentique le rend concret : les agents IA d'achat commencent à utiliser les données produit structurées pour décider quoi recommander et quoi ignorer. Les assets aux métadonnées incomplètes ou non structurées sont de plus en plus signalés comme à faible confiance et écartés.
3. Données de provenance et de droits. À mesure que C2PA, IPTC Media Provenance et standards similaires arrivent à maturité, les agents auront besoin de réponses claires : qui a créé ceci, quand, avec quels outils, sous quels droits, et à travers quelle chaîne de validation ? Les DAM qui captent déjà cela seront agent-ready d'une manière que les DAM qui traitent la provenance en après-coup ne seront pas. (Plus de détails dans la section suivante.)
Il y a aussi la dimension de fraîcheur : les agents qui prennent des décisions en temps réel sur des données obsolètes deviennent erratiques. Cadence de rafraîchissement, lineage et alignement de la source de vérité avec les systèmes PIM, MAM et CMS comptent davantage dès que les agents entrent dans la boucle — les humains tolèrent l'incohérence par exception ; les agents la propagent à l'échelle.
La vérité inconfortable, répétée par chaque analyse crédible que j'ai lue en 2026, est que les organisations sous-investissent dans les fondations de données et sur-investissent dans le choix du modèle. Les travaux propres de McKinsey suggèrent qu'environ 70 % des initiatives en IA générative butent sur des problèmes de données. Dans le DAM, cela se traduit par des agents d'enrichissement qui ne produisent rien d'utile parce que la taxonomie source est incohérente, ou des agents de gouvernance qui signalent tout parce que la charte de marque n'a jamais été traduite en règles vérifiables par la machine.
Si 2024-2025 fut l'ère du « est-ce que le modèle peut le faire ? », 2026 est l'ère du « pouvez-vous prouver ce qu'il a fait, avec quelles données, sous quelles règles ? ». Pour les équipes DAM, trois forces convergentes — les standards d'authenticité du contenu, l'AI Act européen et les questions non résolues sur les données d'entraînement — transforment la provenance d'un nice-to-have en composante du périmètre de conformité.
L'authenticité du contenu est passée à l'âge industriel.
La spécification C2PA (Coalition for Content Provenance and Authenticity), fondée par Adobe, Microsoft, Google, BBC et Intel, intègre des manifests cryptographiquement signés directement dans les fichiers médias. La spec C2PA v2.0 a été ratifiée en 2024, le programme de conformité a été lancé mi-2025, et la Content Authenticity Initiative compte aujourd'hui plus de 6 000 membres dans le monde. La release IPTC 2025.1 ajoute quatre champs spécifiques à l'IA dans le standard IPTC Photo Metadata. Le Sony PXW-Z300 amène les Content Credentials dès la captation, et France Télévisions a commencé à publier des programmes d'information signés C2PA fin 2025 — exactement le type de signal d'adoption qui aspire tous les systèmes en aval, DAM compris, dans le standard. La couverture du Media Provenance Summit IPTC à Toronto (avril 2026) a clairement montré que l'industrie de l'information passe du pilote à la production.
Pour le DAM en particulier, cela se traduit en quatre questions concrètes :
• Préservation à l'ingestion. Le DAM préserve-t-il les métadonnées XMP et C2PA existantes à l'ingestion, ou les efface-t-il silencieusement lors du transcodage ?
• Préservation à l'export. Les pipelines d'export ré-intègrent-ils les champs IPTC et C2PA, ou le preset par défaut supprime-t-il toutes les métadonnées pour réduire la taille du fichier ?
• Capacité d'injection. Le DAM peut-il écrire les champs IPTC 2025.1 IA sur des assets arrivés sans — par exemple, les sorties brutes de Midjourney ou Stable Diffusion ?
• Re-signature C2PA. Si le DAM modifie les métadonnées, sait-il re-signer le manifest C2PA ? Sans re-signature, la chaîne se brise et les vérifieurs en aval rejettent l'asset.
L'AI Act européen devient opérationnellement contraignant le 2 août 2026.
À partir de cette date, les obligations de transparence de l'Article 50 s'appliquent : fournisseurs et déployeurs doivent garantir que le contenu généré ou modifié par IA (images et vidéos comprises) est clairement étiqueté comme tel. Les fournisseurs de modèles GPAI doivent publier un résumé public de leurs données d'entraînement et tenir une politique de conformité au droit d'auteur. Les sanctions atteignent 35 M€ ou 7 % du chiffre d'affaires mondial, le montant le plus élevé étant retenu. Pour les organisations opérant dans l'UE — et cela inclut la majorité de la base client DAM avec laquelle je travaille — cela impose de nouvelles exigences à chaque système en aval qui touche à des assets générés par IA, y compris le DAM. « Nous ne savions pas que c'était généré par IA » ne sera plus une position défendable à partir d'août 2026.
La question éthique des données d'entraînement ne se résoudra pas en 2026.
La directive européenne sur le droit d'auteur permet aux créateurs de réserver leurs droits contre l'entraînement d'IA, et l'AI Act exige des fournisseurs GPAI un résumé des données d'entraînement — mais la mécanique pratique se négocie encore en jurisprudence et en Codes de Pratique. Pour les équipes DAM, les questions éthiques pertinentes sont concrètes : les outils génératifs que votre organisation utilise sont-ils entraînés sur des jeux de données que votre direction juridique défendrait sereinement ? Lorsque vous fine-tunez sur vos propres assets de marque, verrouillez-vous aussi les biais qu'ils transportent ? Lorsque l'IA localise une campagne pour un marché que vous sous-représentez dans vos données, le résultat est-il authentiquement adapté, ou sourdement médiocre ? Le biais des modèles dominants vers l'anglais et les références culturelles dominantes est bien documenté, et la seule mitigation dans les workflows DAM est la revue humaine structurée aux points où l'agent rencontre le marché.
Trois mouvements opérationnels que je suggère dès maintenant :
• Faire de la préservation, l'injection et la re-signature C2PA des critères de procurement. La plupart des éditeurs DAM en sont aux débuts ici ; demandez une démo avec de vrais assets signés, pas une slide de roadmap.
• Mettre en place un registre de contenus IA. Chaque asset généré ou substantiellement modifié par IA reçoit un flag, le nom du modèle, le prompt, l'opérateur, l'horodatage et un statut de revue. Voilà à quoi ressemble la préparation à l'Article 50 en pratique.
• Codifier votre politique d'éthique IA en règles vérifiables par la machine, là où c'est possible. « Ne pas générer d'images de personnes réelles identifiables », « ne pas localiser d'allégations bien-être en FR/DE sans revue juridique », « tagger chaque asset entièrement généré par IA comme tel à l'export ». Les agents de conformité appliquent ce qui est structuré. Ils ne peuvent pas appliquer ce qui ne vit que dans un PDF de politique.
La provenance n'est pas une fonctionnalité que votre DAM possède ou non. C'est une chaîne — captation, ingestion, édition, export, publication — et le DAM est le maillon que la plupart des organisations contrôlent le plus directement.
Quelques points pratiques que je me retrouve à répéter à mes clients :
• Auditer vos métadonnées avant d'acheter vos agents. Une évaluation de santé métadonnées de deux semaines évite généralement une erreur à six chiffres.
• Traiter le support MCP et le support C2PA comme des critères de procurement, même sans cas d'usage immédiat. L'optionalité a une valeur.
• Résister à la tentation des « 20 agents configurés en semaine 1 ». Démarrer avec deux ou trois cas d'usage à fort volume et faible risque (alt-text, enrichissement simple, recadrage de base). Mesurer. Calibrer. Puis étendre.
• Codifier vos règles de marque, conformité et éthique dans une forme structurée avant de demander à un agent de les appliquer. « On-brand » n'est pas un prompt ; c'est une checklist qui doit exister quelque part de lisible par les agents.
• Préparer août 2026 maintenant, pas en juillet. Les obligations de transparence de l'Article 50 deviennent applicables dans trois mois. Étiquetage des contenus IA, résumés de données d'entraînement et préparation à l'audit sont les demandes pratiques.
• Investir dans le rôle humain. Le bibliothécaire DAM de 2024 devient l'opérateur d'agents de 2026. Profil de compétences différent, probablement personne différente.
• Rester indépendant des éditeurs là où c'est possible. Bynder, Aprimo, Adobe, Frontify, Acquia, MediaValet, Wedia, Canto, Papirfly, Cloudinary, CELUM — tous se déplacent dans des directions globalement similaires, avec des architectures, pricing et philosophies d'intégration très différents. Le bon choix dépend de votre volume de contenu, de votre profil réglementaire, de votre empreinte géographique, et de la part du stack agentique que vous voulez posséder versus consommer.
L'IA agentique dans le DAM est sincèrement enthousiasmante, et pour la première fois depuis longtemps, l'écart entre les démos et ce que les systèmes en production peuvent réellement délivrer se referme. Mais la valeur ne sera pas répartie uniformément. Elle reviendra aux organisations qui ont fait le travail ingrat — taxonomie, métadonnées, provenance, gouvernance, architecture d'intégration — avant l'arrivée des agents.
Les agents arrivent de toute façon. La seule question est de savoir s'ils trouveront quelque chose d'utile, et de digne de confiance, sur quoi travailler en arrivant.
Sources : State of DAM 2026 de Bynder (1 800 managers, 7 marchés) ; Huddart / WoodWing State of AI in DAM & Content Operations 2026 (271 professionnels) ; Forrester Wave Q1 2026 DAM Systems ; Content Authenticity Initiative (contentauthenticity.org) ; IPTC Media Provenance Summit Toronto 2026 ; spécification C2PA v2.0 ; AI Act européen (Règlement 2024/1689) — Article 50 et dispositions GPAI applicables au 2 août 2026 ; analyse dampioneers sur la maturité MCP ; McKinsey sur les défis d'implémentation de l'IA générative.








